Automating the updates to my datasets using kafka, spark and airflow.
[data engineering datasets airflow kafka spark streaming docker python pyspark Finally, I have some time and will to post again.

In all seriousness, I find it very hard these days to carve time to dedicate to personal projects. However, I was finally able to finish the implementation of a data pipeline to automatically update the shot chart datasets used by shot_chart which I intend to document on this post.
Motivation
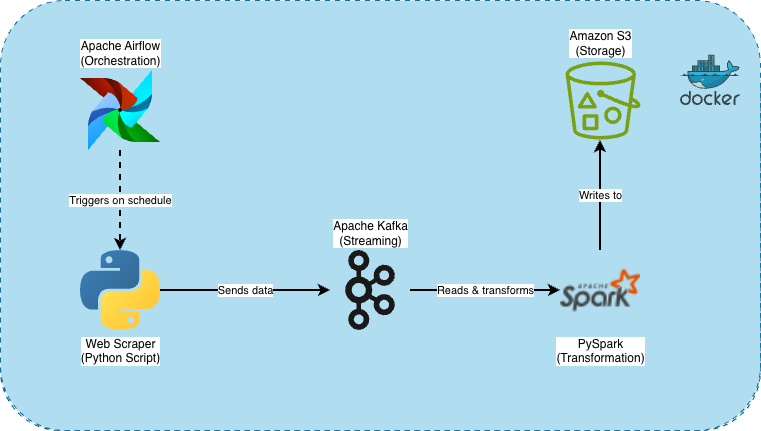
There are two main things that prompted me to build this pipeline: I needed a way to automatically update the charts near realtime and I also wanted to experiment with some of the industry standards in Data Engineering. Therefore, I decided to build the pipeline using technologies like airflow, apache kafka and spark. Before you ask, of course this is overkill in this scenario. These tools are designed to deal with petabytes of data, but you now know why I chose to use them. It’s merely a learning exercise.
Requirements
At a high level, this pipeline needs to:
- Run this scraper on schedule
- Merge the data to an existing dataset.
Technologies and their purpose:
As I mentioned earlier, I used the following tools:
- Airflow: to orchestrate the ETL jobs.
- Apache Kafka: for data streaming and integration
- Apache Spark: to apply transformations (feature engineering) to the dataset.
Pipeline diagram:
Github repo:
Here’s the Github repo which contains a README that goes over setup and how to run the pipeline:
updating-datasets-data-engineering
Pipeline in action:
Next steps:
Now that the datasets are up to date near real-time, there are plenty of new applications we can develop. We can try to feed these data to some models to predict outcomes, analyze win probability etc. More to come on this.