PII redaction using LLM: a prompt engineering introduction
[langchain prompt engineering python LLM Mistral PII redaction using LLM: a prompt engineering introduction
This post is an attempt to get my hands dirty with prompt engineering. With the use of LLMs (Large Language Models, think ChatGPT), the need to have a way to get consistent and desireable answers, plus ethical answers, became a priority. There are other methods to accomplish this, like fine tuning the model. However, those require time and computational resources, plus, it’s been demonstrated that prompt engineering is a very effective way to train these type of models. There are plenty of posts discussing this. However, my aim is to actually share the code via a Jupyter Notebook.
Why PII redaction?
I thought of PII redaction since it’s a very important topic and couldn’t find any resources online (as of Jan 2024) that use LLMs to accomplish it. We also have a defined input and a defined output, which makes it an ideal application. Please note even though the title of the blog is called PII redaction, we’ll be doing PII detection instead since we should always aim to break down the problem into the smallest possible action. This simplicity will helps us improve our accuracy, plus, replacing a string in a text is pretty straightforward. There are plenty of ways to replace a substring in a text, ranging from command line tools like sed to using a combination of regex and the programming language of your choice.
Quick Note
There are newer, more advanced techniques (CoT, automatic prompts…). I haven’t made my way into those yet, but I’m planning on doing so very soon. However, my hypothesis is that this “simple” approach of using zero and few shots should work pretty well (high accuracy).
Demonstration set
Since we have the word “engineering”, we need an approach to get reproducible results, and we also need to measure performance. We will need a demonstration set for that. We’ll use examples to test the accuracy of our solution.
Input:”My social security number is 23424234234” Output:”23424234234”
Input:”Here’s my credit card number 2123-1231-2312-1231” Output:”2123-1231-2312-1231”
Input:”Send it to my address 234432 Indiana AVE SE” Output:”234432 Indiana AVE SE”
Input:”786-709-8545 is my phone number” Output:”786-709-8545”
Input:”I ate the veggie bowl” Output:”I don’t know”
Input:”Mi numero the pasaporte es A78369” Output:”A78369”
Input:”cesar_dummy@gmail.com” Output:”cesar_dummy@gmail.com”
Input:”My birthday is in two weeks” Output:”I don’t know”
Input:”isfgk9482SD is the password” Output:”I don’t know”
Prompt candidates
Now we’ll come up with some prompts to test. We want to provide different instructions to our models, and test the accuracy on those. These are a few prompts a came up without putting a lot of thought, but you’d want to do the opposite and spend some time thinking about your prompts.
- “Identify PII information in the text and provide it as the output”
- “Detect PII information in the text”
- “Identify PII information in the text and return such values”
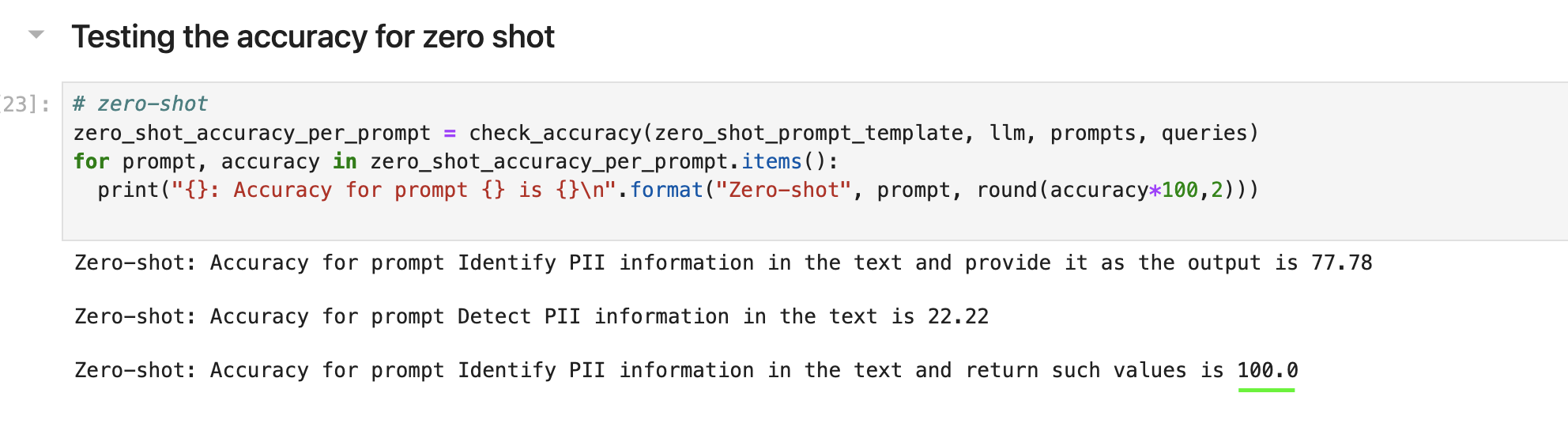
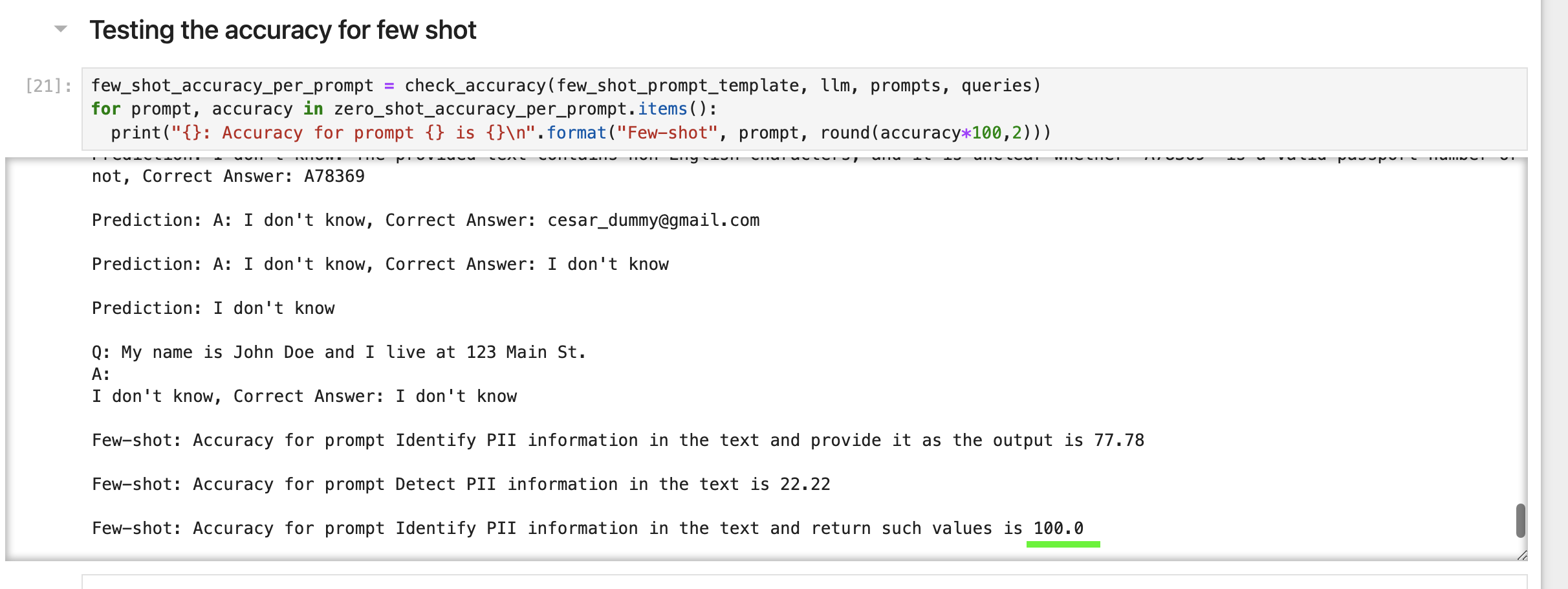
Testing
Now my favorite part! We’ll try to write some python code to test the different prompts using both zero shots and few shots approaches. To implement this, I used langchain and HuggingFace. Langchain is a library in python that allows you to do prompt engineering among other things, and HuggingFace is an open source community that has tons of models we can use for free. The notebook has comments in it for more information.
Link to Notebook.
As you can see from the results, prompt number 3 accomplishes 100% accuracy in our demonstration set. Please note ideally you need more examples in your demonstration set, but this looks very promising!
Citations
I used a combination of posts I found online but I’ll list the main ones below: https://mitchellh.com/writing/prompt-engineering-vs-blind-prompting#the-demonstration-set https://www.pinecone.io/learn/series/langchain/langchain-prompt-templates/